1. MySQL limit的性能实践
mysql的分页功能,在数据量大的情况下,即便有索引,也还是很慢。
做个实验:新建一个最简单的表:
CREATE TABLE `t_test` (
`id` BIGINT(20) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`)
)
然后写个程序,往表里面插入2000万条数据,然后做下面实验:
| SQL | 先执行10次后,再执行的耗时ms |
|---|---|
| SELECT id FROM t_test LIMIT 10000,10 | 3 |
| SELECT id FROM t_test LIMIT 100000,10 | 28 |
| SELECT id FROM t_test LIMIT 1000000,10 | 280 |
| SELECT id FROM t_test LIMIT 10000000,10 | 4500 |
| SELECT id FROM t_test LIMIT 20000000,10 | 6900 |
可见,即便是在只搜索索引(index索引覆盖)的情况下,只要有大的limit offset,那么查询时间和offset是O(n)线性增长。
如果没有limit大offset,例如第20000000个id是20022780起,那么这样查询速度很快:
| SQL | 先执行10次后,再执行的耗时ms |
|---|---|
| SELECT * FROM t_test WHERE id>=20022780 ORDER BY id LIMIT 10 | 1 |
| SELECT id FROM t_test ORDER BY id LIMIT 10 | 1 |
出现上面的情况,可以感性的理解为,limit大offset对索引并没有效果,为什么没有效果?因为:
mysql的b树索引记录了索引字段(可以为组合索引)的大小顺序,存放的格式为(索引字段,key),但是索引没有记录下当前值之前的记录数量,这个记录在实际场景中意义也不大,因为where条件中刚好全是索引字段的,很少。
所以,limit大offset,免不了要全量地扫描数数。
解决这个问题的思路:
- select的字段尽量用索引的字段,例如id,拿到id之后,再用in去select出全部需要的字段。这种方式用到索引覆盖。
- 从业务含义出发,限制limit的offset的最大值,这么多翻页实际上没有太多业务价值,搜索引擎最多也就100页,每页50个。
但是本质上,limit大offset的问题并没有解决,无论加什么索引,不可能把offset是几十万几百万的sql优化到几十毫秒的级别。而根据id来遍历全部,应该使用where id>xx limit 10的方式,id由应用自己记录,即类似于应用代码自行实现游标。
2. 关联查询的3种写法
在两个表有关联的查询时,有三种写法,从理解程度或sql的内聚程度上有区别,性能也有区别。构造了一个例子来试试:
| 表名 | 说明 | 记录数 |
|---|---|---|
| t_course课程表 | 字段:自增id; 课程名称name; 课程分类category | 100万 |
| t_student 学生表 | 字段:自增id; 学生名称name; 学生选课程id->课程表id | 500万条 |
数据方面:课程的分类为100类,分类按A1到A100命名,每类10000个课程,课程名随机,课程表不按分类或名称排序,完全混乱。每个课程报选的学生平均为5个,学生表不按课程id排序,也是完全混乱的。
为这两个表建立索引:t_student的couse_id 和 t_course的category。创表语句如下:
CREATE TABLE `t_student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(64) DEFAULT NULL,
`course_id` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `ci` (`course_id`)
) ENGINE=InnoDB
CREATE TABLE `t_course` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(64) DEFAULT NULL,
`category` varchar(64) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `c` (`category`)
) ENGINE=InnoDB
现在需要查询报选了课程类型为A1的所有学生,有三种写法:
1. join写法
SELECT a.* FROM t_student a JOIN t_course b ON a.course_id=b.id
WHERE b.category = 'A1' limit 1000
SELECT COUNT(a.id) FROM t_student a JOIN t_course b ON a.course_id=b.id
WHERE b.category = 'A1'
2. in的写法
SELECT * FROM t_student WHERE course_id IN (
SELECT id FROM t_course WHERE category = 'A1'
) limit 1000
SELECT COUNT(*) FROM t_student WHERE course_id IN (
SELECT id FROM t_course WHERE category = 'A61'
)
in子查询有两种:1. 查询条件和父表无关。2. 查询条件涉及到父表。后者查询会很慢,应尽量避免,改用join查询。参考
设想一个需求,查询课程名称和学生名称相同的同学:
SELECT * FROM t_student a WHERE course_id IN (
SELECT id FROM t_course b WHERE a.name=b.name
) LIMIT 1000
耗时23.1秒,因为在这个例子中,并没有出现课程名称和学生名称相同的学生,所以实际上数据库全表扫描了所有数据,才发现没有匹配的。
3. exists子句写法
SELECT * FROM t_student a WHERE EXISTS (
SELECT 1 FROM t_course b WHERE a.course_id=b.id AND b.category='A1'
) limit 1000
SELECT COUNT(*) FROM t_student a WHERE EXISTS (
SELECT 1 FROM t_course b WHERE a.course_id=b.id AND b.category='A1'
)
测试数据结果
在一台几年前的笔记本上安装virtualbox+debian虚拟机,再在虚拟机上使用docker安装了mysql 5.5,5.6,5.7,8.0四个版本,测试结果数据如下。(说明:下面耗时是执行查询A*等几次后,再换个课程类型Ax查询的时间,在普通电脑上测试)
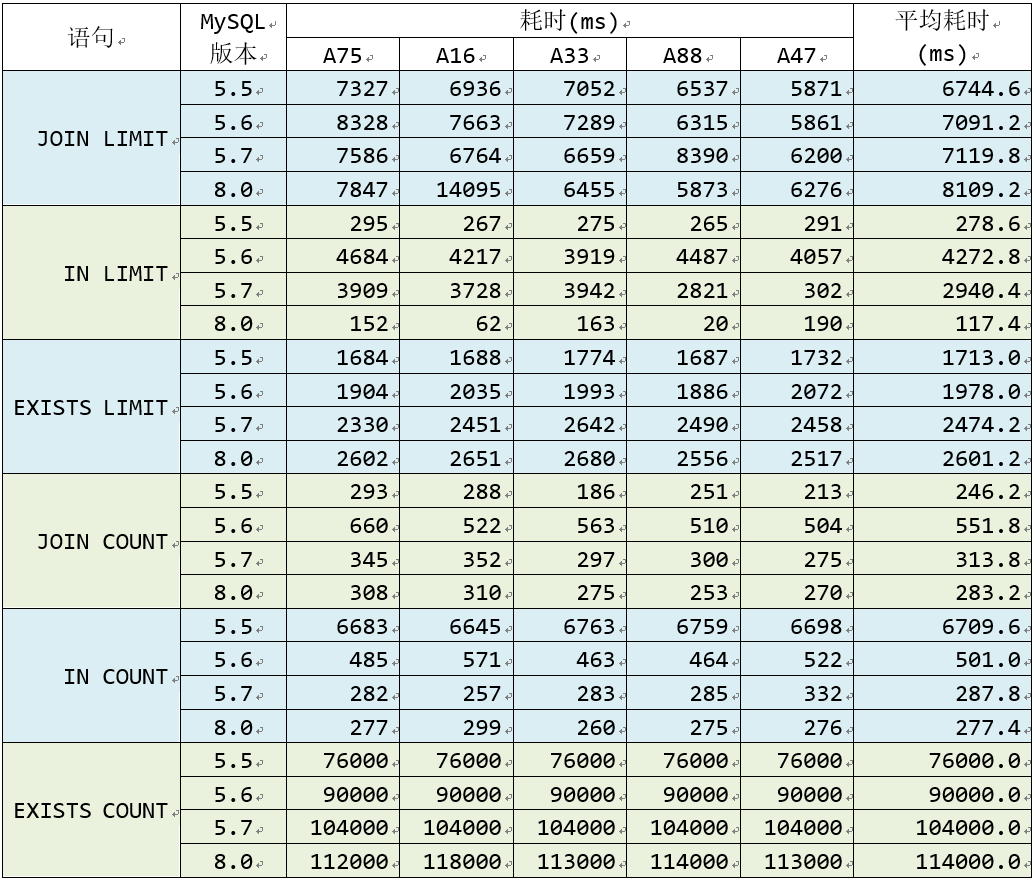
一些结论:
- 获取满足条件的前1000个数据,纯子查询的in比join快。而查询总数则join更稳定。
- in查询方式在不同mysql版本中差异较大。如果还使用5.5版本,要特别注意子查询问题。8.0版本对in查询方式效果最佳。
- exist count计算总数非常慢。
说明
以上实验测试数据是sapluk完成的